

ScrapeBox or SB in short is already a household name and often considered the Swiss army knife for any black hat SEO campaigns. ScrapeBox is a powerful SEO tool that you can build thousands of links, comments or even scraping articles on the Internet within 5 minutes or less.
While ScrapeBox is very common on the darker side of the world, it is also a very popular tool for white hat SEO. Even Neil Patel had a guide on how to use ScrapeBox which you can find it here, Quick Sprout.
This tutorial is all about using ScrapeBox and transforming it from a famous black hat SEO tool into a crazy, devastating and powerful white hat SEO builder. These are some of the very powerful SEO techniques which can either boost your website ranking multiple times (if done correctly) or totally destroy it. You have been warned!
This article is long and thus, I would recommend you to bookmark this for future reference.
[Tutorial] Get high PageRank sites using ScrapeBox
I use ScrapeBox to find high PR blogs which I could leave comments or even applying for guest posting opportunities. Instead of spending the whole afternoon (just assuming) or probably days manually finding quality blog sites with Google or CommentLuv search, ScrapeBox can basically automate the whole process in just a few minutes ‘¦ literally.
ScrapeBox is an excellent tool when it comes to off page SEO.
What is ScrapeBox?
>> Get ScrapeBox here! <<
Using shared or private proxies
If you are thinking of using ScrapeBox, you need to run on proxies. This is to avoid your IP(s) being blocked by Google. Since ScrapeBox does the process a thousand times faster than human, it is a no brainer to use proxies to avoid Google detection and penalization. To run ScrapeBox functions properly, you would require at least 10 proxies.
You have been warned. You can use ScrapeBox without proxies but your IP will be banned by Google within days. Tested and proven!
There are two types of proxies which you can use with ScrapeBox which are shared or private proxies. Shared means that that proxy could be shared among 3 to 10 users while private proxies are specific to you only. If you are looking for good proxy company, I would highly recommend Squid Proxies. They have top notch customer service and they assist to setup proxies within an hour or less. I got mine within 5 minutes after completing the checkout and it only cost around $1 per private proxy.
>> Click here to get Squid Proxies as low as $0.42 each! <<
I am going to be very honest with you; ScapeBox is not very user-friendly and it would require a little learning curve before you can put it to good use. But don’t frust! This I will be creating more tutorials on how to use ScapeBox and you should bookmark it for future reference.
Scraping keywords
Finding high PageRank sites is a 3-steps process when you are using ScapeBox and the first is to find the proper keywords. While you can use keyword research tools such as Google Keyword Planner or Long Tail Keyword, ScrapeBox has an inbuilt keyword scrapper feature.
ScrapeBox makes keyword scraping as easy as A, B and C. Each process takes less than 5 minutes to perform which is a huge time saver for marketers and niche bloggers.
Step 1 – Scraping related keywords
- We all heard about long tail keywords and the effectiveness of it. The same concept applies when you are using ScapeBox. You want to find both exact keywords and related keywords to maximize your search results.
- Click on Scrape and select Keyword Scraper.
- This will opens up a box that has two columns. Key in your keyword on the left column and select Scrape.
- A list will related keywords will show on the right column and delete those which are unrelated.
- [Optional] Click on Transfer Left and repeat the first process. Delete off those keywords which are unrelated and you would be able to get a complete list of keywords on your right column.
- Click Send to ScrapeBox and press Close.

Note: Scraping the related keyword twice would provide you a better and bigger list of related keywords which is highly recommended to improve your search results later.
Step 2 – Choosing the right footprint
Footprint is also known as command and this is how to control ScrapeBox to perform a specific task. By default, ScrapeBox comes with several basic footprints which you can use. In this tutorial, you do not need to use any. Instead, I will show you how you can build your own footprint.
In the Harvester column, key in either one of these codes:
- site:.com (you may replace .com with .net, .org, .info etc)
- intitle:keyword
- inurl:keyword
- intext:keyword
For example, using ‘site:.com’ will enable ScrapeBox to search for sites which has the specific keyword and the URL comes from dot coms only.
Fill the relevant footprint and then, click on Platform. There is a full list of platforms you can choose from but I always go with WordPress only.
Now, you are ready for the next step.

Step 3 – Setting up proxies
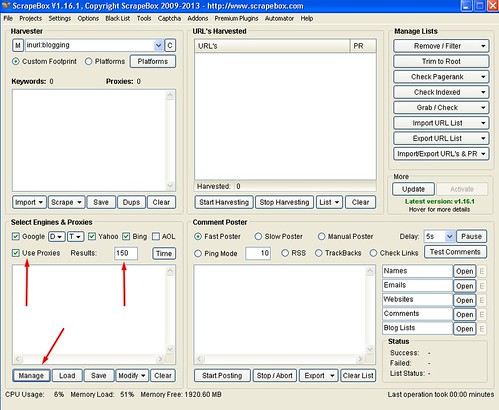
The list of keywords will be visible in the Keywords column and now, you need to set up proxies. If you have yet to get any proxies, you can get some cheap but quality proxies from Squid Hosting.
- Enable Use Proxies.
- Paste your proxies in the Select Engines & Proxies and click Manage.
- A box will open up and your proxies will be visible in it.
- Click on Test Proxies and select Test All Proxies. This is to ensure that all your proxies are working properly. Status of the proxies must be in green which is good while red means the proxies are down. Contact your proxy supplier if you find any of those proxies which are not working and they will provide you with new ones.
- Press Close.
- Note: You may select the type of search engine to use and I highly recommend Google, Yahoo and Bing only. As for the number of results, I usually set it to 150 as anything more than that usually provides low quality results.
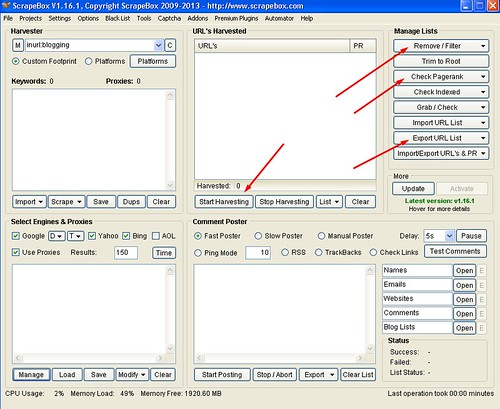
Step 4 – Harvesting URL’s with ScrapeBox and find high PageRank sites
This is where ScrapeBox will do its magic. Select Start Harvesting and ScrapeBox will automatically search for related blog sites which the keywords you selected.
Depending how fast your computer, proxies and Internet speed are, it will generate a list of blog URL’s which you can start working on. While ScrapeBox would probably return thousands of results, it is time to trim down those links.
The process of trimming down the links is to find high PageRank sites only.
This is how you trim your URL results:
- Select Remove / Filter and select Remove Duplicate URL’s
- [Optional] You can further trim down the links by using either selecting Remove URL’s Containing or Remove URL’s Not Containing.
- Select Check PageRank and Get Domain PageRank
Checking of PageRank would take some time and therefore, leave ScrapeBox running. Once the results are out, you can either export it out using excel using Export URL List and select Export as Excel (.xlsx) or the lazy way (my style) which is to click on the PR button to sort it automatically.
Now, you have completed the whole scraping process and you should have a list of quality sites you can start commenting, request for guest posting, communicate with the webmasters in terms authority building etc.
ScrapeBox is a dangerous SEO tool. You have been warned!
While SB could do wonders for your SEO campaigns, it is also a very dangerous tool which can kill your blog ranking overnight. For starters, I do not suggest using it directly on your blog. Instead, you could try to use it on your secondary sites to start building backlinks.
Wait! Do you like this tutorial? I would really appreciate if you can share this article for me using the social icons below.